I was grateful to be invited by Business/Arts’ artsvest national program to develop and present a brand new 90-minute workshop on AI Tools for Smaller Arts Organizations. This workshop was first presented virtually to a national live audience of about 65 participants on October 8, 2025.
AI is no longer mere hype—it’s already reshaping how organizations across many sectors work including in the arts. Ready or not, AI is here and it is improving rapidly. In this session we will talk about what AI is good and bad at and how you can decide where to use AI tools in your organization.

This hands-on virtual workshop cuts through the noise and focuses on practical tools you can use right now to save time, stretch resources, and sharpen your communications. We’ll look at embedded AI tools in your office productivity software, operating system level AI, and we’ll take a deeper dive into Generative AI. You’ll learn how to decide whether to use AI for everyday tasks: drafting grants, marketing copy and materials; analyzing data; or streamlining admin tasks. We’ll explore affordable AI tools that fit into the systems you already use, from Canva, Mailchimp to presentations and spreadsheets, and highlight where automation could free up your team’s time.
We’ll also leave you with a simple governance checklist to keep your organization’s data, voice, and values safe. This session is designed for staff and board members who need clarity, not jargon, and want to see real-world results for their time and effort.
To book this workshop or a custom tailored working session for your group, get in touch with Inga Petri.
On the spectrum of AI capabilities
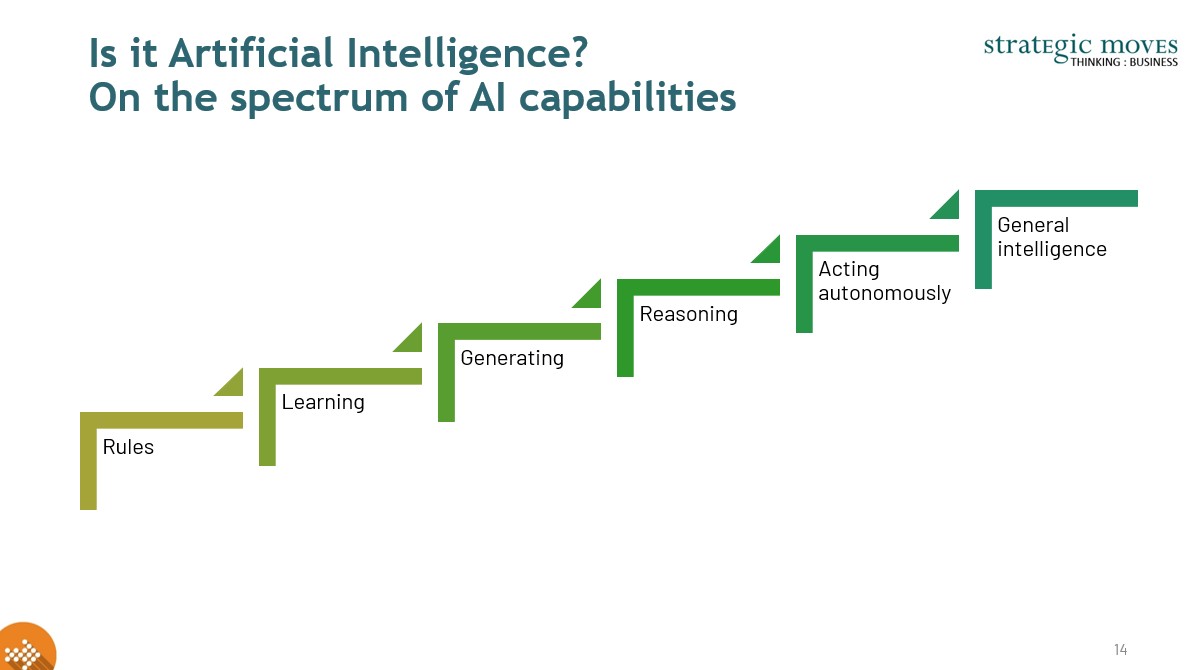
Artificial Intelligence (AI) is not a single monolithic technology but a spectrum of capabilities that range from basic automation to highly sophisticated generative and agentic systems. For small arts organizations, clarity about these distinctions is critical. It allows leaders to separate hype from reality and make grounded choices about how to incorporate AI into their workflows.
Ethical AI Use
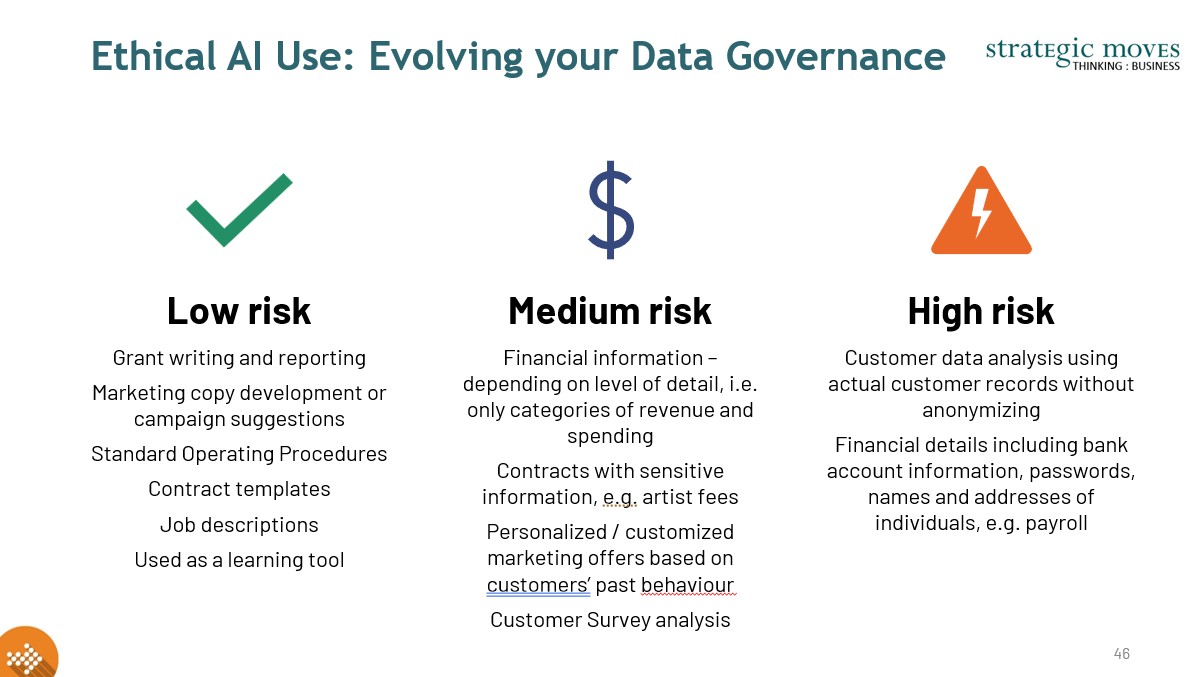
While AI tools offer transformative potential, their adoption raises serious ethical and governance questions. For arts organizations that act as stewards of culture, creativity, and community trust, responsible use of AI is non-negotiable.
Privacy and Data Security
AI systems often require access to organizational or audience data. Whether training an AI on past grant reports or allowing cloud-based tools to process ticketing data, organizations must safeguard personal information. Under Canadian privacy law—including the **Personal Information Protection and Electronic Documents Act (PIPEDA)**—organizations are obligated to secure data, limit its use, and obtain meaningful consent.